
Sajjad Iranmanesh,
Department of Software and Information Technology Engineering
18/12/2024
Syncify: A Strongly Eventual Consistent Peer-to-Peer File Synchronization System for Distributed Edge Environments
https://syncify.ca
Presentation Outline
1. Introduction
- Background and Motivation
- Edge Computing and IoT Landscape
- Challenges in Edge Computing and IoT
- Existing Approaches & Their Limitations
2. Technical Background
- Understanding CRDTs
- Hybrid Logical Clocks (HLC)
3. System Architecture
- Tree CRDTs for Directory Management
- Content Addressing and MerkleDAG
- Distributed Hash Table (DHT)
- Pub/Sub System
4. Implementation
- System Components
- Handling Edge Cases
- Live System Demo
5. Evaluation
- Performance Analysis
- Comparison with Existing Solutions
- Scalability and Resource Usage
6. Conclusion
- Key Contributions
- Future Work
Background and Motivation - Edge Computing and IoT Landscape
Key Requirements:
- Real-time data processing
- Continuous operation
- Resilient to network issues
- Resource-efficient synchronization
Motivating Scenario: Edge Robotics:
- Autonomous warehouse robots with local AI
- Share updated AI models for navigation and object recognition
- Maintain consistent configuration files across robot fleet
- Need to propagate knowledge when new situations encountered
Edge Computing & IoT: A Rapidly Growing Paradigm
- From centralized cloud ➔ distributed edge processing
- Computing closer to data sources
- Lower latency, better privacy, reduced bandwidth





Challenges in Edge Computing and IoT
Network Challenges:
- Intermittent connectivity → Robots in poor coverage zones
- Limited bandwidth → Large AI model sharing
- High latency → Real-time robot coordination
- Network partitions → Isolated robot groups

Data Management Issues:
- Data generation at edge → Continuous sensor data
- Concurrent updates → Multiple robots learning simultaneously
- Consistency requirements → Synchronized AI models
- Real-time synchronization → Immediate knowledge sharing
- Data integrity and availability → Reliable model distribution
Device Constraints:
- Limited processing power → Local AI inference
- Storage limitations → Model and sensor data storage
- Battery constraints → Continuous operation
- Heterogeneous capabilities → Different robot types
Existing Approaches & Their Limitations

- Pure P2P Systems (e.g., Freenet, BitTorrent)
- Focus on content sharing and distribution
- DHT-Based Systems (e.g., CFS, PAST)
- Structured overlay for content routing
- Hybrid Systems (e.g., FastTrack)
- Combined centralized/decentralized elements
Key Building Blocks in Distributed Storage:
Main Categories of Current Solutions:
- Centralized Cloud Sync (CCS):
- Single point of failure, high latency
- Poor partition tolerance
- Peer-to-Peer Sync (P2PS):
- High connection overhead
- Complex conflict resolution
- Content-Addressed Systems (e.g., IPFS-Sync):
- Update inefficiency
- Limited directory support
Existing Approaches & Their Limitations
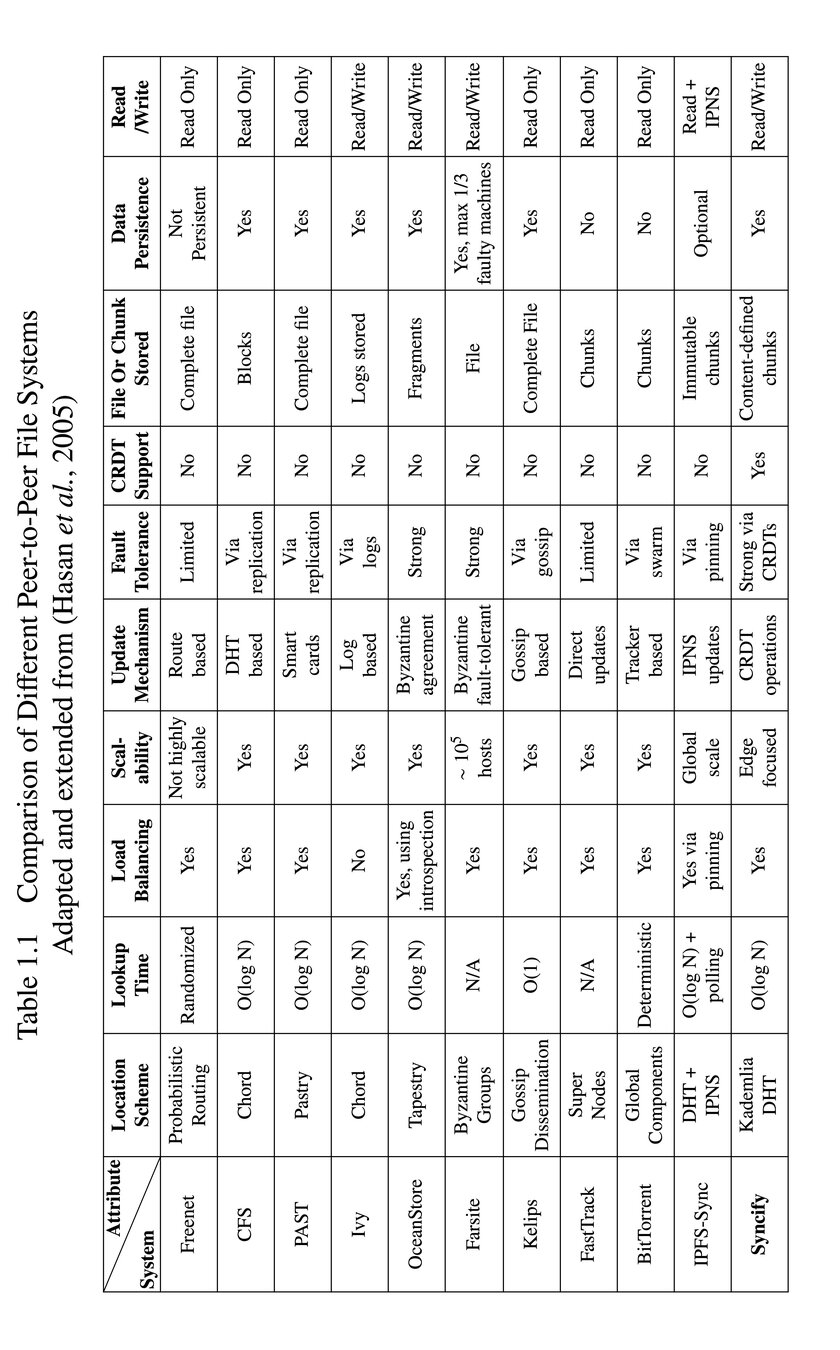
Why is Syncing So Hard?
- Two main problems: Unreliable ordering and conflicts
- Solution must work 100% of the time
- Need for seamless synchronization with no data loss
Unreliable Ordering
- Distributed nature leads to different event ordering
- Naive mutations lead to inconsistent states
- Need for a solution that embraces distributed timelines
Eventual Consistency
- Embracing multiple timelines in distributed systems
- Goal: Produce the same state on each device
- Challenges in achieving consistency with out-of-order changes


Solving Unreliable Ordering
- Assigning timestamps to changes
- Per-device clocks (e.g., Vector Clocks, Hybrid Logical Clocks)
- HLCs: Serializable and comparable timestamps
Lamport Clocks vs. Hybrid Logical Clocks (HLC) in CRDTs
Why We're Using HLC:
1. Consistency in distributed systems
2. Efficient conflict resolution
3. User-friendly versioning (e.g., 01-01-2024)
Lamport Clocks:
• Logical clock for ordering events
• Scalar value increases monotonically
• Establishes partial ordering of operations
• Preserves causal relationships
Limitations:
• Abstract integers (1, 2, 3...) as versions
• No correlation to real date-time
Hybrid Logical Clocks (HLC):
• Combines physical and logical time
• Preserves causality with real-time correlation
• Versions correlate to physical time
class HybridLogicalClock(
val timestamp: Timestamp = Timestamp.now(Clock.System),
val counter: Int = 0,
val node: NodeID = NodeID.mint(),
)001728518867187:00001:b7e8083dc5b2d32c
Conflict-free Replicated Data Types (CRDTs)

Definition: Data structures for replication across multiple computers
Key properties:
- Replicas can be updated independently and in parallel
- No need for coordination between replicas
- Guaranteed conflict-free operations
- Convergence towards the same state
Use cases: Collaborative software, shared documents, databases
Advantages:
- Strong Eventual consistency
- Partition tolerance
- Supports offline work and P2P connections
What problems does CRDT solve?
Conflict-free Replicated Data Types (CRDTs)
Key Properties of CRDTs: Commutative, Associative, and Idempotent
Commutative
Definition: The order of operations doesn't affect the final result
Example: a + b = b + a
Associative
Definition: Grouping of operations doesn't affect the final result
Example: (a + b) + c = a + (b + c)
Idempotent
Definition: Applying an operation multiple times has the same effect as applying it once
Example: max(max(a, b), b) = max(a, b)

Eventual Consistency (EC):
-
Three key properties:
1. Eventual Delivery
Updates reach all correct replicas
2. Convergence
Same updates lead to same final state
3. Termination
All methods complete in finite time
-
May require conflict resolution
Strong Eventual Consistency (SEC):
- Includes all EC properties
-
Adds Strong Convergence:
- Replicas with same updates are in same state
{
x: 300,
timestamp: "001728520334648:00000:a7008ecf53def814"
}{
z: 114,
timestamp: "001728520334642:00002:a89653d0ab9fa9fc"
}{
x: 8,
timestamp: "001728520334641:00001:a89653d0ab9fa9fc"
}{
y: 73,
timestamp: "001728520334640:00000:a89653d0ab9fa9fc"
}{ }LWW-Map
{
y: 73,
timestamp: "001728520334640:00000:a89653d0ab9fa9fc"
}{
x: 8,
timestamp: "001728520334641:00001:a89653d0ab9fa9fc"
}{
z: 114,
timestamp: "001728520334642:00002:a89653d0ab9fa9fc"
}{
x: 300,
timestamp: "001728520334648:00000:a7008ecf53def814"
}{ x: 300 }{ x: 300, y: 73 }{ x: 300, y: 73, z: 114 }{ x: 300, y: 73 }{
x: 300,
timestamp: "001728520334648:00000:a7008ecf53def814"
}{
z: 114,
timestamp: "001728520334642:00002:a89653d0ab9fa9fc"
}{
x: 8,
timestamp: "001728520334641:00001:a89653d0ab9fa9fc"
}{
y: 73,
timestamp: "001728520334640:00000:a89653d0ab9fa9fc"
}{ }LWW-Map
{
y: 73,
timestamp: "001728520334640:00000:a89653d0ab9fa9fc"
}{
x: 8,
timestamp: "001728520334641:00001:a89653d0ab9fa9fc"
}{
z: 114,
timestamp: "001728520334642:00002:a89653d0ab9fa9fc"
}{
x: 300,
timestamp: "001728520334648:00000:a7008ecf53def814"
}{ x: 8 }{ x: 8, y: 73 }{ x: 300, y: 73 }{ x: 300, y: 73, z: 114 }Syncify Architecture


Tree CRDTs: Managing Hierarchical Data in Collaborative Systems
Why Tree CRDTs?
- Manage hierarchical relationships in distributed systems
- Enable real-time collaboration on tree-structured data
- Resolve conflicts automatically
- Maintain consistency across multiple replicas
Challenges in Implementing Tree CRDTs
- Concurrent operations leading to conflicts
- Maintaining tree properties (no cycles)
- Efficiently handling moves and reordering
- Balancing consistency, availability, and partition tolerance

Taken from [1]
[1] https://loro.dev/blog/movable-tree
Tree CRDTs: Managing Hierarchical Data in Collaborative Systems
Key Operation in Movable Tree CRDTs
- Move node
Our Approach
- Based on "A highly-available move operation for replicated trees" paper [1]
- Uses move operation as primary action
- Deletion handled by moving to TRASH node
- Applies Lamport timestamps for global ordering
- Implements undo-redo mechanism for conflict resolution
- How to introduce global order to operations?
[1] Kleppmann et al., "A highly-available move operation for replicated trees" (2022)

Tree CRDTs: Managing Hierarchical Data in Collaborative Systems
Benefits and Performance
- Enables real-time collaboration on tree structures
- Automatic conflict resolution
- Efficient version control and history traversal
- Benchmarks show good performance for typical operations
Conclusion
- Tree CRDTs crucial for managing hierarchical data in collaborative systems
- Our implementation balances efficiency and functionality
- Enables complex collaborative scenarios on tree-structured data


Deletion and Movement of the Same Node





















Moving sub trees in a tree
Ancestor Node Deletion and Descendant Node Movement







How Dropbox handles cycles












Movement of Different Nodes Resulting in a Cycle
Concurrent moves of same node




















Tree-CRDT Algorithm in Action: Step-by-Step Example
Concurrent moves of same node


CRDT-Based Directory Operations: Move Operation and Log Entry Structures
Tree CRDT Demo
Taken from https://madebyevan.com/algos/crdt-mutable-tree-hierarchy/
Syncify Architecture - MerkleDAG

Adding and getting content
Your Computer
Syncify
The Web
file://path/go/index.html
http://domain.com/path/to/index.html
mtwirsqawjuoloq2gvtyug2tc3jbf5htm2zeo4rsknfiv3fdp46adomain.com => IP Address




MerkleDAG for content addressing and operation list

Syncify Architecture -DHT
DHT (Distributed Hash Table)

A distributed Hash Table(DHT) provides a 2-column table maintained by multiple peers.
Each row is stored by peers based on similarity between the key and the peer ID we call this distance.
The DHT is to provide:
- Content Discovery (ContentID => PeerID)
- Peer routing (PeerID => IP, protocol)

How it Works:
-
When content added:
-
Generated unique CID, stored locally
-
DHT stores only "provider records" (CID → Provider nodes)
-
-
Content Discovery Flow:
-
Request content by CID
-
DHT returns provider list
-
Direct peer-to-peer transfer
-
Syncify Architecture - Pub/Sub
Distributed Pub/Sub
- Without relying on any piece of centralized infrastructure
- Adapts as your network grows
Floodsub
- Simplest possible protocol
- Routing is achieved by flooding
Pros:
- Simple to implement
- Very robust
- Minimum latency
Cons:
- Bandwidth inefficient
- Unbounded degree flooding(wastes a lot of resources)
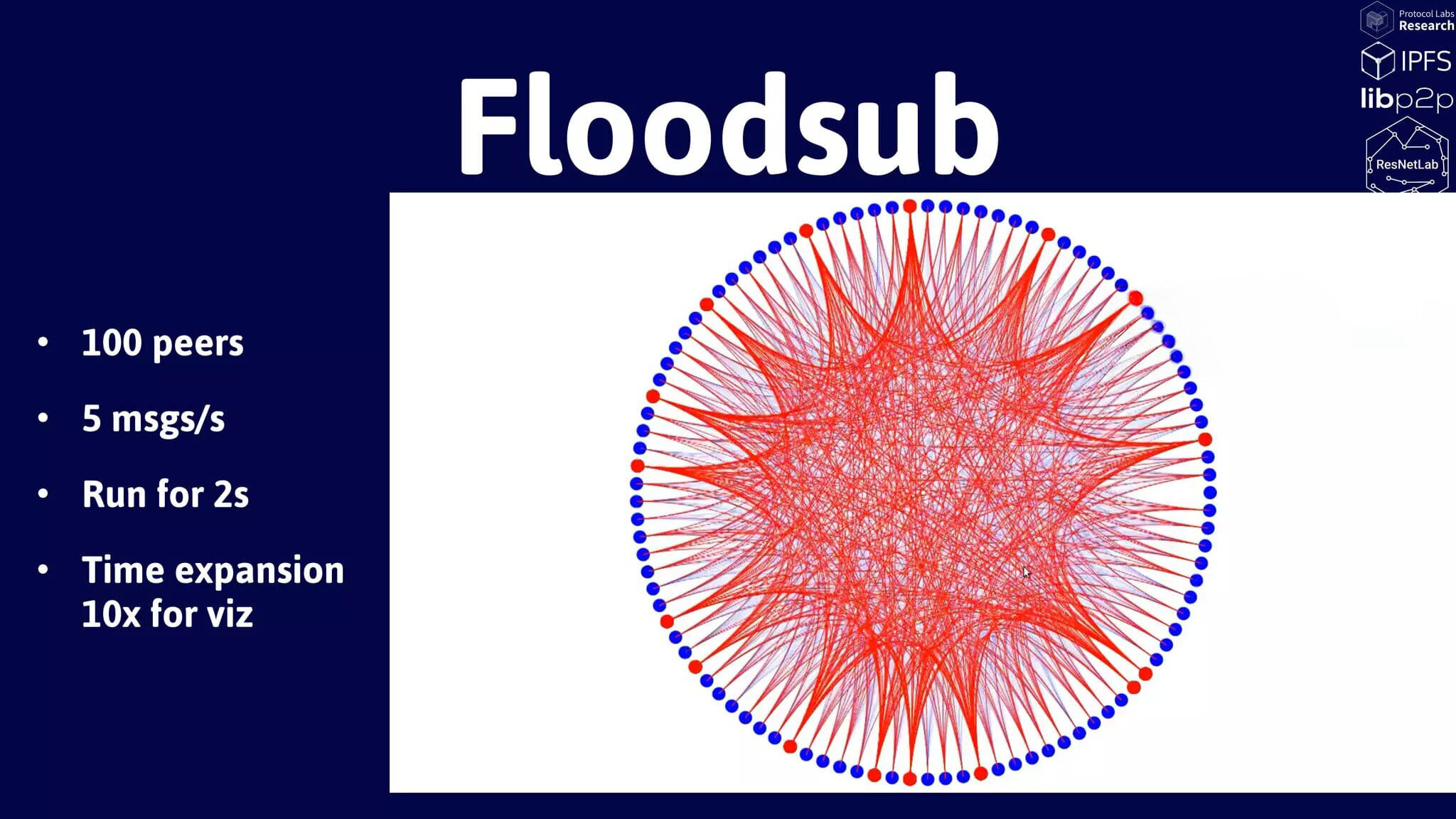
Features:
Taken from [1]
[1] docs.libp2p.io/concepts/pubsub/overview/
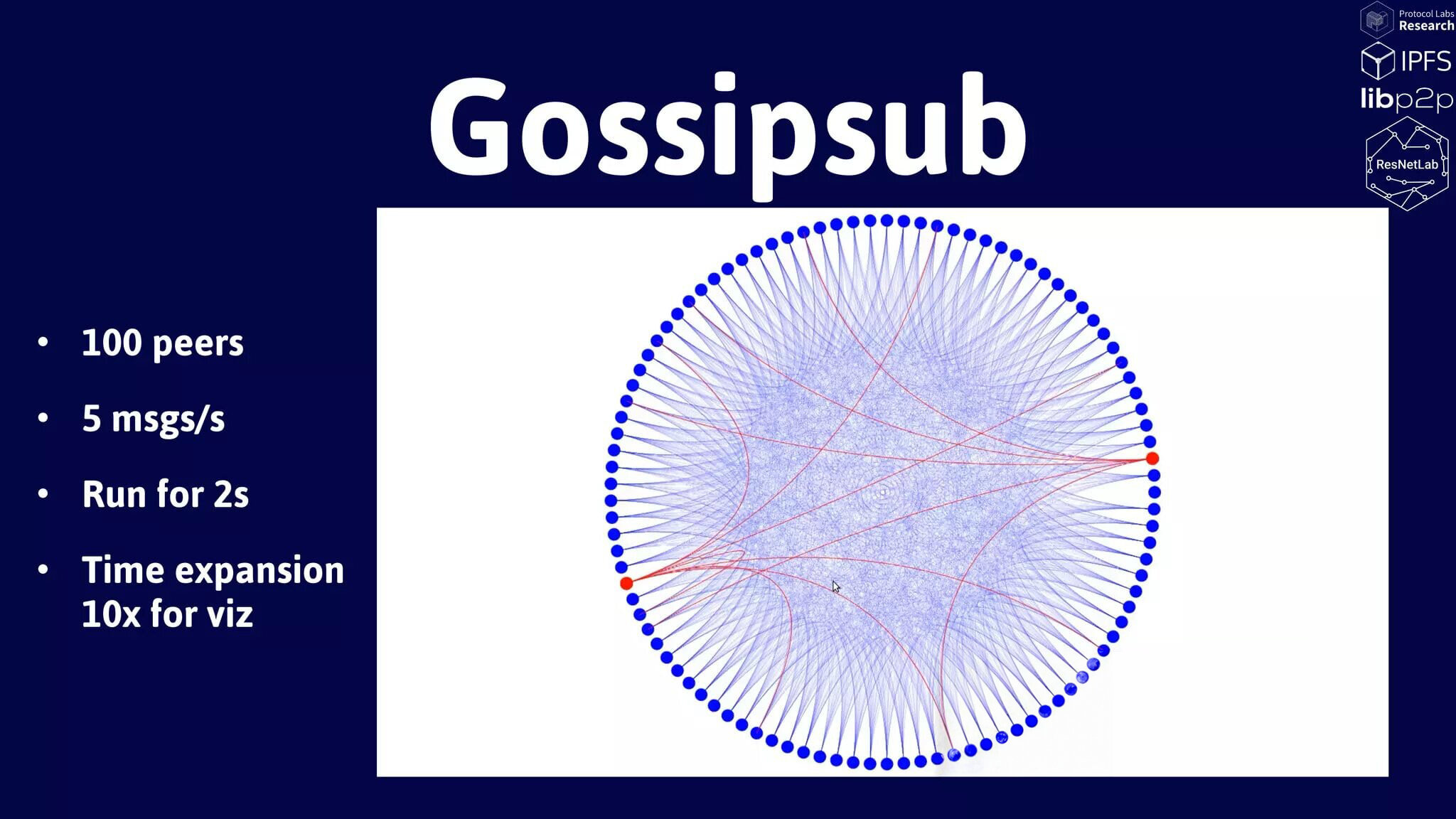
GossipSub - Key Features of GossipSub
- Bandwidth efficient
- Scalable to large networks
- Low latency message propagation
- Resilient to network churn
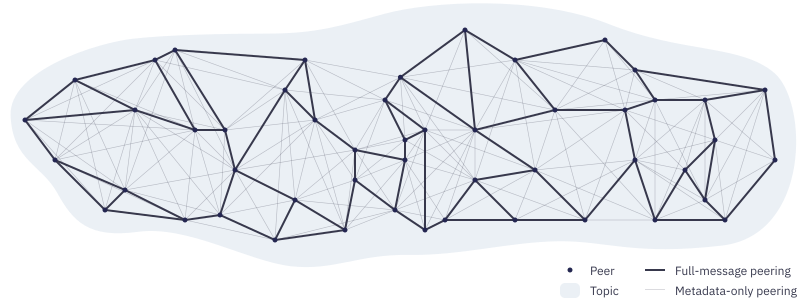
Taken from [1]
Distributed Pub/Sub
[1] docs.libp2p.io/concepts/pubsub/overview/
GossipSub
Subscribing and Unsubscribing
Taken from [1]
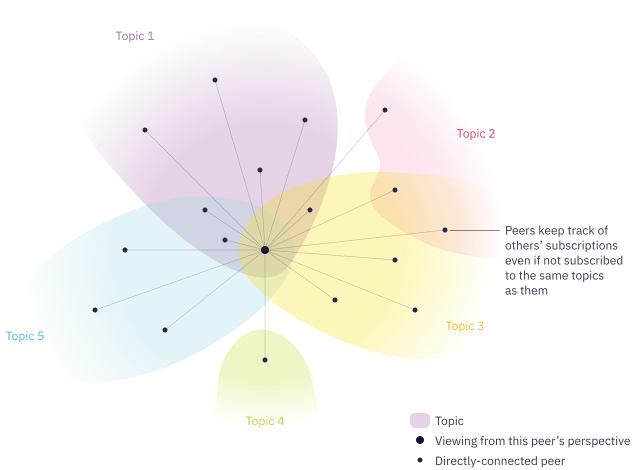
- Nodes keep a partial view of the network
- Nodes announce their subscriptions on joining the network
- Subscriptions are updated through the lifetime of the node


When a node joins
Overtime
[1] docs.libp2p.io/concepts/pubsub/overview/
Interaction Between Components














Handling Missed Updates




-
Linked List of Operations:
- Each operation points to the previous operation
-
Periodic Root CID Sharing:
- Nodes periodically broadcast the root CID of their operations list via the pub/sub system.
- This broadcast could happen at set intervals or after a certain number of new operations
-
Catch-up Process:
- When a node realizes it's behind (based on Lamport clock or missing operations), it can request the current root CID from peers.

Demo
Experiment 1: Syncify vs. rsync vs Syncthing and IPFS-SYNC: Performance Under Varying Network Conditions
Superior Performance
- Up to 90% faster than centralized systems
- 15% faster than closest competitor (IPFS-SYNC)
Scalability Advantage
- Logarithmic growth vs exponential in others
- Only 20-25% increase in sync time when quadrupling nodes (25 → 100)
Consistency & Reliability
- Best performance stability (10% variance)
- Consistent across all network conditions
Architecture Benefits:
✓ DHT-based content addressing minimizes bandwidth usage
✓ Pub/sub mechanism reduces update overhead
✓ CRDT enables parallel operations

Experiment 2: File Retrieval Resilience Under Node Failures

Key Findings:
- k=5 maintains 90% success rate even with 50% failed nodes
- System remains resilient up to 10% failures across all k-values
- Higher k-values provide stronger resilience at cost of more resources
- Critical data → k=4,5
- Non-critical data → k=2,3
Choose k based on data criticality:
Experiment 3: Node Failure Recovery Time
Setup:
- 1,000 total nodes
- Failures: 0-20% of nodes
- Two scenarios: Light vs Heavy Updates
Key Findings:
- Recovers from 20% node failures (200 nodes) in <10 seconds
- Logarithmic scaling in recovery time
- Graceful performance degradation
- Maintains stability under heavy loads

Experiment 4: Impact of Active Replication Levels on Recovery Time
Test Setup:
- 1,000 edge nodes
- Replication levels: k=1, 3, 5
- File sizes: 1MB, 5MB, 10MB
- Node failures: 0-20%
Key Findings:
- Higher replication → faster recovery
- k=3 provides optimal balance
- System remains stable with 20% node failures
- Good scalability across file sizes



Experiment 5: Convergence Time Analysis

Key Findings:
- Non-linear scaling with concurrent updates - system handles moderate concurrency well
- Higher k-replication increases convergence time by 40-50%
- Large files (>50MB) take 2.5x longer to converge
Implications:
- Adaptive replication strategies needed for large files
- System performs best with moderate concurrency levels
- Trade-off between fault tolerance and convergence speed
Bottom Line: System shows good scalability for typical edge workloads but needs optimization for extreme scenarios (high concurrency + large files + high replication)
Experiment 6: Network Partition Recovery Time Analysis

Excellent Scalability:
- Sublinear recovery time increase as network grew from 10 to 60 nodes
- System maintained stable performance across different deployment scales
Strong Performance Under Stress
- Recovery times stayed under 30 seconds even in worst-case scenarios
- Successfully handled high numbers of conflicting operations
Important Trade-offs Identified
- Higher k-replication → Better fault tolerance but longer recovery times
- Clear relationship between conflict count and recovery duration
Real-world Implications
- Demonstrated suitability for edge environments prone to network partitions
- Predictable behavior enables reliable deployment planning
Test Parameters:
- Nodes: 10-60
- Conflicts: 1 to N (N = node count)
- K-replication: 1-5
- Recovery metric: Time from reconnection to full consistency
Experiment 5: Impact of File Chunking on Synchronization Performance

Key Findings:
- Maximum Impact: 97% reduction in sync time for large files (1000 MB) with small changes (1%)
Performance Benefits:
- Small changes (1-10%): Massive improvement
- Large changes (50%): Still 30-50% faster
- Most effective for files > 100MB
Practical Implications:
- Perfect for edge computing where bandwidth is limited
- Especially valuable for large files with frequent small updates
- Minor overhead for small files (<5MB) - negligible trade-off
File chunking makes synchronization dramatically more efficient, especially for large files with small changes - exactly what we need in edge environments
Experiment 5: Resource Utilization in Diverse Operational Scenarios
Efficient Scaling:
- CPU: 34% → 68% (1→100 updates/min)
- Memory: 65MB → 245MB
- Peak load: 87.6% CPU, 320MB RAM

Network Partition Recovery:
- Continuous operation during 10-min partition
- Successfully reconciled 127 conflicts
- Stable recovery (48.8% CPU)
Conclusion & Future Works
Conclusion:
- Syncify: Directory and file synchronization system for edge/IoT
-
Outperforms traditional approaches in key areas:
- Improved synchronization latency
- Enhanced scalability
- Efficient conflict resolution
- Better performance during network partitions
Future Works:
- Adaptive Replication Strategies
- Enhanced Privacy-Preserving Techniques
- Machine Learning Integration
- Cross-Platform Compatibility
- Energy-Aware Optimizations
- Integration with Edge Computing Frameworks
- Real-Time Collaboration Features
- Compliance and Regulatory Considerations
Thank You for Your Attention!
For any questions or further discussion, feel free to contact me at:
